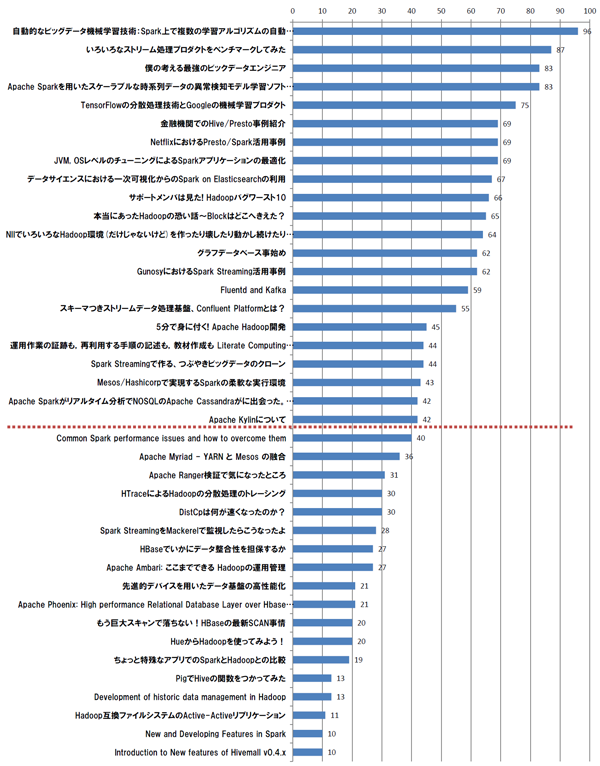
Hadoop / Spark Conference Japan 2016のライトニングトーク企画に、多くの方から候補案をエントリ頂きました。会場や時間の制約のため、全員に発表頂くのは難しいため、投票により選定させてもらうことになりました。投票はWeb上のフォームを通じて、ひとり最大10件の候補を選択する仕組みで、2016年1月21日~1月27日に実施しました(全280件の投票)。
結果は次のグラフの通りとなり(PDF版)、42票以上を獲得した22件(ランチタイム12件+懇親会時 10件)の案を選定することになりました。エントリ頂いた皆さま、投票頂いた皆様、ご協力ありがとうございました。
イベント当日のライトニングトークのプログラムは、イベントページをご確認ください。
皆さんから提案頂いた案は次のとおりです。
- 【僕の考える最強のビックデータエンジニア】
オンプレ、クラウドが競合する中で今後のビックデータエンジニアはどうあるべきか、どの様な技術を持ったエンジニアが今後生き延びて行けそうかを話したいと思います。 - 【Common Spark performance issues and how to overcome them】(英語での発表)
Spark is advertised as a framework which can run up to 100 times faster than Hadoop’s MapReduce. This can be true but only if we pay attention to the details. In this LT I will present some of the most common performance-related problems Software Engineers make and how to deal with them. - 【グラフデータベース事始め】
Sparkの活用と共に俄然注目を浴びるグラフデータベース。Apache Tinkerpopの仲間たちも加えて、更に勢力を増していますが、そもそもグラフってなんだかわかんない。とりあえず構築してみたものの何やっていいのかわかんない。そんなあなたをもうひと押し!一般的なグラフの基礎から分析の基本的な考え方をお伝えします。 - 【5分で身に付く! Apache Hadoop開発】
Hadoopのパッチを書いてみたい、でも、敷居が高そうだしやっぱりやめておこうかな、・・・と思っているそこのあなた! パッチを書くことはとっても簡単です! パッチを書き、それがマージされるまでの流れについて、本LTで紹介してみせます。 - 【いろいろなストリーム処理プロダクトをベンチマークしてみた】
ストリーム処理でOSSのStorm, Spark streaming, Flink streaming, Samzaでベンチマークをとってみました。各プロダクトの特徴、ベンチマーク結果を簡単ながら紹介します。ストリーム処理のOSSを数多くベンチマークした資料はあまりなく、ベンダーの情報でないので参考になればと思います。 - 【スキーマつきストリームデータ処理基盤、Confluent Platformとは?】
最近リアルタイム処理用のプロダクトとしてKafkaが広まってきていますが、スキーマレスなため、どのようなメッセージが入っているか管理が困難、データ形式更新時に影響範囲が見えないといった課題があります。これらの課題を解決し、組織全体のストリームデータ基盤を構築するためにKafka開発チームによって提案されているのがスキーマつきストリームデータ基盤OSS、『Confluent Platform』です。Confluent Platformのアーキテクチャや機能、使いどころや利点について紹介します。 - 【Development of historic data management in Hadoop】
JTのHistoryData管理、MR2のHistoryServer、TimeLineServer、TimeLineServer v.2.それぞれの違い、期待、良かったところ、足りなかったところについての軽い話 - 【サポートメンバは見た! Hadoopバグワースト10】
NTTデータでは2011年からHadoopサポートサービスを実施しており、顧客からの問い合わせに日々回答を続けています。これまでのサポートサービスの歴史で出くわした、Hadoopの多種多様なバグについて、影響範囲・対処法も含めて一挙紹介します。 - 【DistCpは何が速くなったのか?】
データ移行やバックアップには欠かせないお馴染みのDistCpですが、枯れたツールもまだまだ進化が進んでいます。本LTでは、最新のDistCpで改善されたパフォーマンスについて紹介します - 【もう巨大スキャンで落ちない!HBaseの最新SCAN事情】
HBaseのスキャンには、取得サイズが大きすぎるとOutOfMemoryErrorを誘発する問題がありました。本LTでは、HBase 1.1.0で改善されたスキャンのハンドリングについて紹介します - 【Apache Ranger検証で気になったところ】
Hadoopエコシステムについてのアクセスコントロール機能を提供するApache Rangerについて、Yahoo! Japanで行った検証や、気になったことについて解説します。 - 【GunosyにおけるSpark Streaming活用事例】
弊社でのSpark Streamin活用事例を紹介いたします。全体構成、開発および運用の工夫点、ハマりどころ等。 - 【NIIでいろいろなHadoop環境(だけじゃないけど)を作ったり壊したり動かし続けたりしている話】
国立情報学研究所(NII)では、BIGCHA 2015、トップエスイーなどでHadoopを利用した集中講義を実施したり、研究目的でいろいろなクラスタを必要に応じて構築・運用したりしています。学術機関の利用者ですと、利用目的により必要な構成、設定が異なってきます。例えば、セキュリティの設定を必要としていたり、最新のパッケージを使いたかったり、Hadoop外のツールがほしかったり、付帯的なソフトウェアも含めたかったり、プロビジョニング対象が異なったりなど。これらの、少しずつ異なる環境の構築・運用作業を、JupyterやAnsibleといったソフトウェアを活用しつつ再現可能かつ再利用しやすい形で実施していくことを追求しています。そこでの闘いの記録をお話ししたいと思います。 - 【先進的デバイスを用いたデータ基盤の高性能化】
我々は先進的デバイスを用いたデータ基盤の高性能化に取り組んでいる。本講演では ioDriveを用いたWALの高性能化、分散処理を用いた類似検索の高性能化、RDMAを用いた高速データ処理等について述べる。 - 【Apache Myriad – YARN と Mesos の融合】
HadoopではYARNがクラスタ内のリソースの割り当てを行うリソースマネージャの働きをしていますが、データセンター内の汎用的なリソース管理フレームワークとしてはApache Meses もポピュラーです。Spark, Kafka, Storm, Elasticsearch といった数々のソフトウェアが Mesos に対応し、Apple, Twitter, eBay といった企業が活用していることでも有名です。YARN と Mesos はどこが似ていてどこが似ていないのか、という話から始めて、両者をスムーズに連携させる Apache Myriad をご紹介します。 - 【HueからHadoopを使ってみよう!】
まだコンソールからHadoopを使っていませんか?Hadoopを利用するためのGUIといえばHue。デモを交えながらHueを紹介します - 【データサイエンスにおける一次可視化からのSpark on Elasticsearchの利用】
本LTでは、弊社のデータ分析基盤 DSL(Data Science Lab.)でのSparkの利用ケースを紹介する。DSLでは、蓄積データとリアルタイムデータの一次可視化のために、Elasticsearchを利用している。Elasticsearchに蓄積したデータにもSparkを利用することで、効率よく統計処理・分析が実行できた。本ケースは、ElasticsearchユーザのためのSparkの導入としても役立ち得る。 - 【HBaseでいかにデータ整合性を担保するか】
HBaseでデータ整合性を保つテクニックを紹介します。サイバーエージェントではHBaseを用いたグラフDB「Hornet」を開発・運用しており、ソーシャルグラフデータを日々蓄積しています。Hornetにデータを追加する際には、実データの他にインデックスやカウントデータなど複数のデータをHBaseに追加する必要があります。HBaseでは複数Rowにまたがったトランザクション機能がないので、エラー発生時に、これらのデータが不整合を起こす可能性があります。Hornetでは、このデータ不整合を防ぐべく、HBaseのCoprocessorを用いたり、カスタマイズを行っています。今回は、そのテクニックのいくつかを紹介させていただきます。 - 【本当にあったHadoopの恐い話~Blockはどこへきえた?】
トラブルも無く運用を続けていたHadoop環境。朝出勤してみると、HDFSでブロックが消えるという異常が発生!サーバ故障やDataNode離脱が起きていない状況で何故消えたのか。調査をすると、Hadoopに致命的な罠が潜んでいたのであった… - 【PigでHiveの関数をつかってみた】
データフロー形式で処理を定義することができるApache Pig。SQLライクなApache Hiveに比べて陰は薄いものの、着実に進歩しています。Apache Pigで細かな処理を定義する場合は、独自にユーザ定義関数を作成することが一般的ですが、そのユーザ定義関数として、Apache Hiveで利用するユーザ定義関数が利用できるようになっています。本LTでは、PigでHive関連のUDFを使ってみた話を発表します。 - 【New and Developing Features in Spark】
最近自分が投げたパッチとか、興味深かったパッチの内容を幾つか紹介します - 【Fluentd and Kafka】
Hadoopと組み合わせてよく使われるKafkaとFluentdとの連携について話します. - 【Apache Ambari: ここまでできる Hadoopの運用管理】
OSSのHadoop運用管理ツールであるApache Ambariをご紹介します。Ambariは「Hadoop for Everyone」という大きいビジョンを掲げています。Ambariを使用したHadoopのクラスタ管理、構成管理、クラスタ監視、サービス管理やAmbariの拡張性をお伝えします。また、最新のAmbariアップデートもご紹介します。最新Ambariでここまでできる、Hadoopの運用管理!お楽しみにしてください - 【Apache Kylinについて】
2015年にトッププロジェクトに昇格した低レイテンシクエリ実行エンジンであるApache Kylinについて、Yahoo! Japanでの検証結果も交えつつ、アーキテクチャの概要や効果的な用途について紹介します。 - 【Introduction to New features of Hivemall v0.4.x】
HCJ 2014で紹介して以来、HivemallはRandomForest、Factorization Machines、Matrix Factorization、AdaGrad/AdaDelta等の機能強化を行っている。Hivemall v0.4.1でサポートしている機能と開発ロードマップの紹介を行う。 - 【TensorFlowの分散処理技術とGoogleの機械学習プロダクト】
Googleが公開したMLフレームワークTensorFlowの真価は、いかにしてMLや深層学習の大規模行列演算を分散系にスケールアウトさせるかにあります。本セッションでは、Googleが最近公開したML製品と特長と、それを支えるTensorFlowの分散技術を解説します。 - 【自動的なビッグデータ機械学習技術:Spark上で複数の学習アルゴリズムの自動選択が可能に】
機械学習をビッグデータに適用する際には、各種の機械学習とその並列処理を熟知したデータサイエンティストが不可欠でした。そこで、だれでも機械学習が使えるようにするために、MLLIbはもちろんRやPythonの機械学習ライブラリを含む10種類以上の機械学習アルゴリズムとそのハイパーパラメータの最適な組合せを自動的に探索する技術をSpark上に開発しました。データのサンプリングレートを増やしながら見込みのない組合せを枝刈りすることで、網羅的に機械学習をすると1週間程度かかる5000万件規模のデータを、数十分の1にあたる数時間で学習する事ができるようになりました。講演においては、想定利用シーン、開発技術の原理、および、動作概要のデモをお見せします。 - 【金融機関でのHive/Presto事例紹介】
金融機関が数百TB~数PBのデータをHive/Prestoをクラウド上で活用している事例をご紹介します。 - 【Apache Phoenix: High performance Relational Database Layer over HBase for Low Latency Applications】
PhoenixはHBaseデータをSQL使った簡単かつ高速にアクセスさせるためのHBase上のSQLレイヤーです。Phoenixの機能特徴、向いている処理、アーキテクチャ、HBaseの仕組みを活かした高速なクエリやチューニングポイントを技術的に掘り下げてご紹介します。 - 【NetflixにおけるPresto/Spark活用事例】
Netflixが25PBのAmazon S3のデータをPresto/Sparkで活用している事例をご紹介します。 - 【Apache Sparkを用いたスケーラブルな時系列データの異常検知モデル学習ソフトウェアの開発】
様々な機器類を監視するセンサーの時系列データを分析し、異常を検知する手法およびソフトウェアの研究開発を行ってきた。今回紹介するソフトウェアでは、バッチ処理で複数のセンサーから得られた高次元の時系列データから線形のLASSO回帰によりモデルを学習し、異常を識別する。しかし学習時間やメモリー使用量の増大が課題になってきたため、Sparkを活用し分散並列化を行った。SparkにはMLlibという汎用的な機械学習ライブラリが存在するが、今回は使用するアルゴリズムの特徴を考慮し、既存実装を基に新規に開発した。当開発におけるデザインチョイスや性能計測結果について報告する。 - 【ちょっと特殊なアプリでのSparkとHadoopとの比較】
学術的な場において,研究ツールとしてHadoop MapReduceやSparkといった汎用分散処理システムを利用することは少なくない.本研究室で扱っている大規模な分散システム向けのシミュレータがその一例である.今回,大学での研究におけるSparkの利用事例として,シミュレータを用いた研究を紹介する.研究の中で取り組んだHadoop MapReduceからSparkへのアプリケーションの移行についての紹介や,移行の前後でのシミュレータ性能の比較を行う.また,それらから得られたSpark利用における知見を述べる. - 【Apache Sparkがリアルタイム分析でNOSQLのApache Cassandraがに出会った。(ウルルン風)】
オペレーショナルなNOSQLのApache CassandraとApache Sparkでリアルタイム分析をどのように実現できるのか、Open SourceのSpark-Cassandra-Connectorを簡単に説明いたします - 【Spark Streamingで作る、つぶやきビッグデータのクローン】
Apache Sparkを利用したTwitterデータ解析システムの例を紹介します。具体的にはSpark Streamingを使ったNHKの「つぶやきビッグデータ」クローンシステム(オープンソース・ソフトウェア)を作りましたのでシステムの詳細を紹介します。実際に作成したシステムを使って徳島OSC、広島OSC、島根OSCでは会場に展示してもらい、イベントに関するTwitterの呟きを展示してもらいましたのでその結果なども公表します。今回作成したソフトはSparkスタンドアローンで動作し、視覚的にもわかりやすいためSparkを触ったことがないエンジニアがSparkを扱うきっかけになると思います。「Sparkを始めてみたいけど、何に使えるのかわからない」そんな方に特に聞いていただきたい内容になります。 - 【Hadoop互換ファイルシステムのActive-Activeリプリケーション】
ネットワークにおいて合意の問題を解決するためのプロトコルであるPaxosに基づく分散Coordination Engineを使ったApache Hadoop互換ファイルシステム間での複製について紹介する。複数の(異なるディストリビューションも含め)HadoopクラスタでのHA/DR、マイグレーション、Vision-UPが可能。HDFSとアマゾンS3、EMC Isilon等のHadoop互換ファイルシステムとの間での複製も可能となる。Hadoopを複数データセンタへ展開、クラウドとのハイブリッド環境で展開する際のソリューションとして、事例も含めた紹介を行う。 - 【Mesos/Hashicorpで実現するSparkの柔軟な実行環境】
講演ではMesosとDockerの利点を活かし、複数の分析用環境や複数のバージョンを切り替えることのできる柔軟な分析環境の構築、および分析環境が共有・管理される場合のHashicorpConsulを活用した可視性・追跡性の高い管理方法について解説いたします。利用者は開発環境における試作サービスをシームレスに大規模運営に移行することができるとともに、各担当部署の作業負荷を明確に削減することが可能となります。 - 【JVM, OSレベルのチューニングによるSparkアプリケーションの最適化】
本講演では,Sparkアプリケーションをより高速に実行させるため,Sparkを実行するシステム側(JVM,OS)からのパフォーマンスチューニング手法について説明する.TPC-HベンチマークやMLlibのアルゴリズムなど様々なワークロードに対して,GCアルゴリズムやJVMオプション,ExecutorJVM数などを調整するJVM側からの最適化,NUMAやラージページを用いたOS側からの最適化を通じて,Sparkアプリケーションの性能がどのように向上するかについて,Spark1.5および1.6を用いて検証した結果を報告する. - 【Spark StreamingをMackerelで監視したらこうなったよ】
みなさん、Sparkの運用監視ってどうしてますか?私たちのプロジェクトではインフラ周り担当者の負担を考え、最低限使うツールははてな社のMackerelというサービスに統一しています。ではMackerelをどう活用してSparkを運用しているか?その勘所をお話します。 - 【HTraceによるHadoopの分散処理のトレーシング】
Hadoopは多数のサーバノードで分散して処理を行うため、意図しない動作や性能劣化が見られたときに、ログメッセージやデバッガ、プロファイラ等を利用して解析を行うことが難しくなります。Apache HTraceはそのような分散システムの動作を解析するためのツールとして開発され、Hadoopに組み込まれて利用できるようになりました。このセッションでは、HTraceビルトインのツールを利用した、トレース情報の収集および解析の要領などを紹介します。 - 【運用作業の証跡も,再利用する手順の記述も,教材作成も Literate Computing でやってみる】
国立情報学研究所(NII)では、研究者向けのクラウドを運用・サービス提供するに際してLiterate Computing for Reproducible Infrastructure という考え方を提案している。 日々の運用作業の証跡を記録する、そこから手順を整理して再利用する、マニュアルや教材を整備するなど複数局面での計算機利用を、同じような粒度で記述・蓄積することを目的としてJupyterを活用している実践を紹介する。スキルセットの異なる運用者間ひいては利用者との間でもHadoopやSparkなど複雑なインフラの構築やカスタマイズ,運用ノウハウに関する伝達・教示を容易にすること。また,計算機環境の構築・運用・利用のすべての局面において環境のトレーサビリティや再現性を担保できるようにすること。卑近には運用スキルの属人化,ブラックボックス化を避けること。 これらの課題感にLiterate Computingでどこまで対処できたか、できそうか話してみたい。